I’ve built a lot of unofficial software for my schools, Brown University and previously Macalester College. To name a few: an “everything app” called 75grand with dining hall menus, Moodle assignments, building hours, an event calendar, and more; two unfinished course catalogs; and a university shuttle tracker. None of these were developed in partnership with the college (75grand’s success was even met with jealousy from the college).
All of these make heavy use of numerous undocumented APIs, which I have a lot of fun searching for. It’s satisfying to find a clean, reliable, and complete (choose two) data source without having to resort to scraping HTML pages.
In this post I’ll share, in no particular order, some tips for finding and using these APIs.
Search GitHub
In Brown’s case, many student and staff developers have published code publicly over the years that uses otherwise undocumented APIs. GitHub’s code search tool is a powerful way to look for potential endpoints. I used a regex pattern to look for JSON and XML URLs under Brown’s domain: /brown\.edu\/\S*\.(json|xml)/.
With those results, I discovered that Brown’s researcher database is not only open source, but follows the common Rails pattern of returning JSON data for any page ending in .json, such as https://vivo.brown.edu/search.json?q=seth+rockman. This could be very helpful for displaying information about professors in the course catalog I’m building.
There’s also a site called PublicWWW which I find less helpful.
Look out for fetch requests
Keep an eye out for parts of pages that load after the rest of the page or actions that don’t cause a full page refresh—these are signs of the use of fetch (or AJAX) requests to JSON APIs.
For example, the Brown history department’s course catalog stood out to me, and popping open the network monitor, it led me to the motherlode—a GraphQL endpoint.
This turned out to be the best source of course data I had found yet. Unfortunately, the server had disabled introspection (which is where the GraphQL API will tell you its schema), but I was able to guess a few dozen fields. The error messages helpfully suggested fields I hadn’t known about by “correcting” my typos.
WordPress sites come with free APIs
All WordPress sites come with a built-in REST API for accessing posts, pages, media, and more as JSON. Often, site administrators won’t disable many of the endpoints. I built a tool called WP_Snooper that queries for uploaded media, since media on WordPress sites is public even if the posts using it aren’t.
Look at robots.txt files
If they don’t want the robots to see it, maybe you do.
Literally just Google it
I was poking around the Salvation Army’s store locator, and just Googled the API endpoint. To my surprise, it turned up a page generated by ASP.NET with all the available routes and their usage. If anyone wants data about the Wyoming legislature, they’ve got one too. You can find a bunch of them by searching for allintitle:"ASP.NET Web API Help Page".
Another example of this is when I was investigating the Brown sociology department’s course catalog. Their site stood out to me because it still uses an older design that most university sites have switched off of. While there were some fetch requests happening, they were only returning HTML. The interesting data was being loaded on the server. I Googled the endpoint I had, and lo and behold Google had cached a cURL error from the page! Unfortunately, Google was truncating the error message and I couldn’t make out the entire URL. With the Google cache gone, I just guessed bits and pieces of the URL until Google showed me all of it.
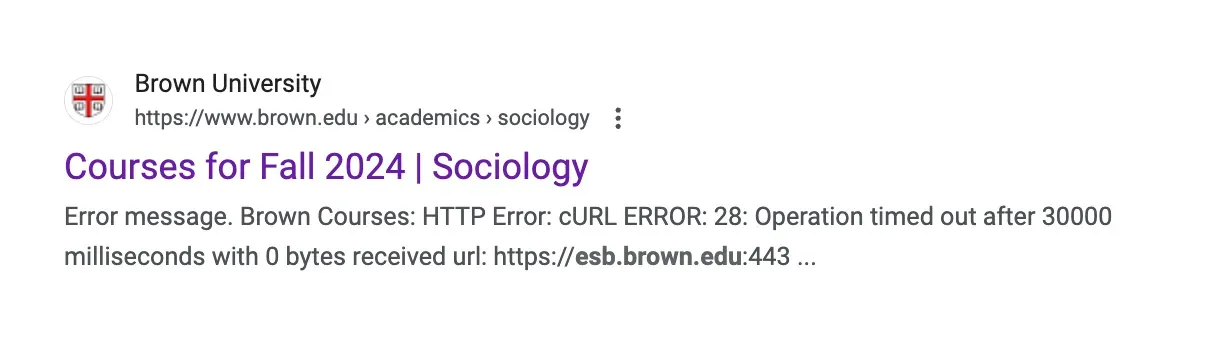
Just guess
Eliot was looking for some course data from Stanford and enlisted my help. We found Stanford Navigator, which appeared to be doing some asynchronous data loading, but it turned out to just be serialized React components from Next.js. So, not knowing if there even was a public-facing endpoint, I just guessed a URL: https://navigator.stanford.edu/api/classes/1252/3109. Easy.
Read and debug JavaScript
An app’s JavaScript can help you find API endpoints and understand their schema and how they’re used. On many older sites, JavaScript is simply concatenated, not minified or mangled. Sometimes you’ll get super lucky and the developer hasn’t turned off source maps.
This was helpful when I was reverse-engineering the Brown University Shuttle’s tracker. Reading the JavaScript, which was barely obfuscated, helped me understand the nuanced semantics of some aspects of the API.
Download mobile apps
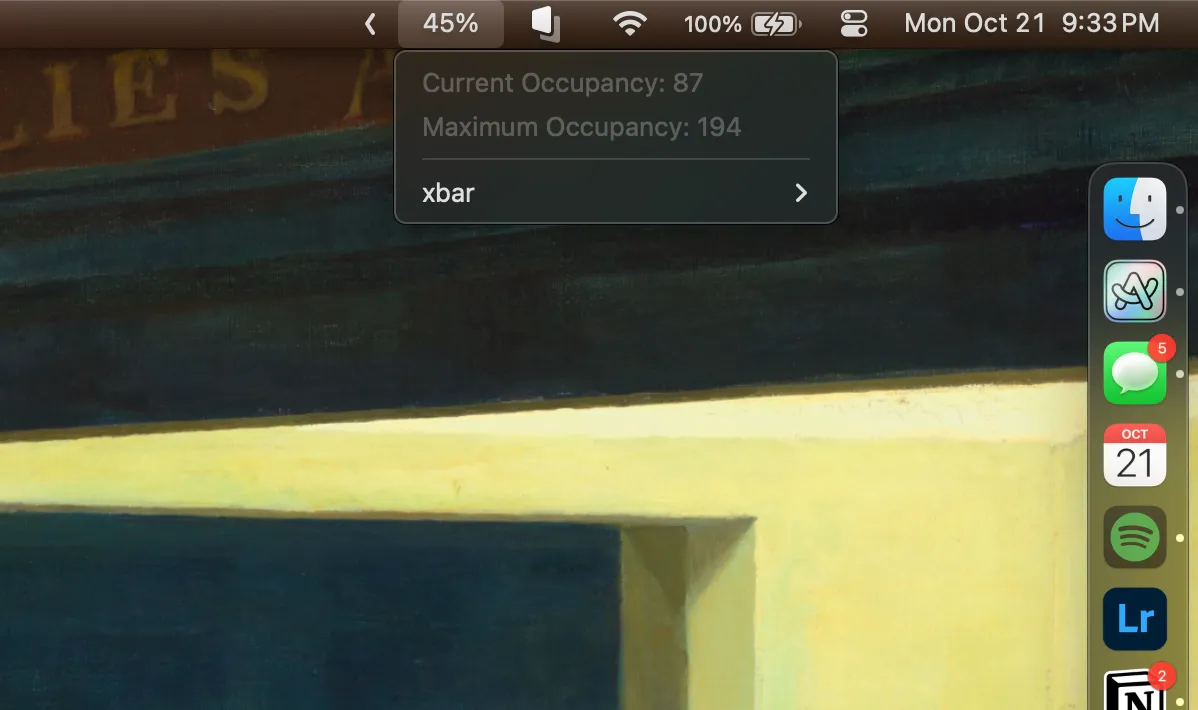
Mobile apps have no choice but to use HTTP APIs. You can easily download a lot of iOS apps through the Mac App Store, then run strings on their bundles to look for endpoints. You can also download Android apps as APKs from various mirrors and decompile them. This is how I found an endpoint that returns the occupancy of Brown’s gym, which I built a menu bar app for.
Use tools
Here are some tools that are useful for reverse-engineering APIs: crt.sh, C99.nl’s subomain finder, WP_Snooper, React Developer Tools, Vue DevTools, Wappalyzer, BuiltWith’s “relationships” tool, PublicWWW, GitHub Code Search, GraphQL Playground, cURL, an API testing tool like Postman, Proxyman, Charles, Asset Catalog Tinkerer, and an APK decompiler.
Finally, while I hope these specific tips are useful, the most effective reverse-engineers are curious, deeply knowledgable about how web apps work, and follow their gut.